반응형
데이터프레임을 활용한 통계작업으로 pivot_table 과 groupby 를 많이 사용합니다.
그런데 다양한 통계데이터 처리를 하기 위해 몇가지 팁을 알면 좀 더 효율적인 작업이 가능합니다.
이번에는 기본적인 피봇테이블 사용과 데이터가 결측치로 없을 때 처리방법,
그리고 여러 컬럼의 데이터를 통계로 한번에 표출하는 방법에 대해 정리하였습니다.
1. 기본 Pivot Table 만들기
일반적인 데이터프레임에서 values, index, columns, aggfunc 값을 지정
👉 aggfunc
sum (합계), count (개수), mean (평균), median (중앙값), min (최소값), max (최대값), std (표준편차)
인덱스 2개, 컬럼 1개에 대한 sum 사용
import pandas as pd
# 샘플 데이터 생성
data = {
'지역': ['서울', '서울', '부산', '부산', '대구', '대구'],
'월': ['1월', '2월', '1월', '2월', '1월', '2월'],
'매출': [100, 200, 150, 250, 120, 300]
}
df = pd.DataFrame(data)
df
지역 월 매출
0 서울 1월 100
1 서울 2월 200
2 부산 1월 150
3 부산 2월 250
4 대구 1월 120
5 대구 2월 300
pivot1 = pd.pivot_table(df,
index=['지역', '월'],
values='매출',
aggfunc='sum')
pivot1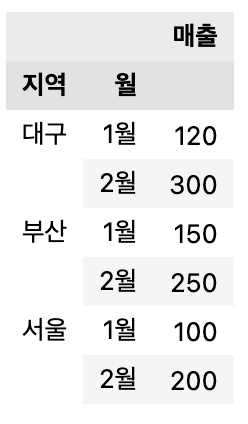
2. Pivot Table 결과 값이 NaN 으로 나올 때 처리
인덱스 2개, 컬럼 1개
fill_value 속성 이용 '0' 으로 값을 채움
# 일부 데이터 제거해서 NaN 발생시키기
df2 = df.drop(1) # 서울 2월 데이터 제거
pivot2 = pd.pivot_table(df2,
index=['지역'],
values='매출',
columns=['월'],
aggfunc='sum',
fill_value=0)
pivot2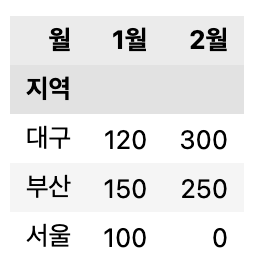
3. 여러 열에 대해 각기 다른 집계 함수 적용
인덱스 2개, 값 2개
aggfunc={'컬럼1':'sum','컬럼2':'mean'} → 컬럼별 다른 연산 적용 가능
data = {
'지역': ['서울', '서울', '부산', '부산', '대구', '대구'],
'월': ['1월', '2월', '1월', '2월', '1월', '2월'],
'매출': [100, 200, 150, 250, 120, 300],
'비용': [50, 80, 60, 90, 55, 100]
}
df = pd.DataFrame(data)
df
pivot3 = pd.pivot_table(df,
index=['지역', '월'],
values=['매출', '비용'],
aggfunc={'매출': 'sum', '비용': 'mean'})
pivot3


4. 하나의 열에 대해 여러 집계 함수 동시에 적용
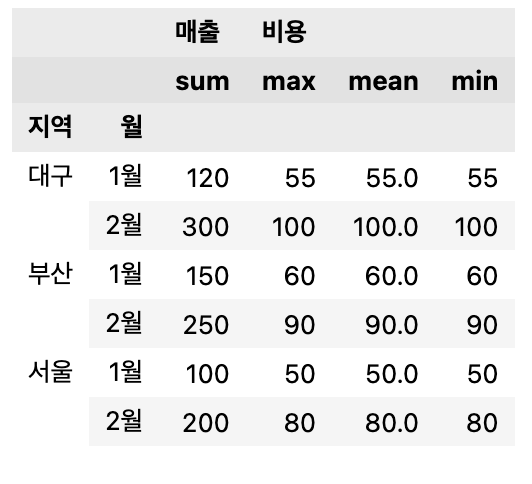
pivot4 = pd.pivot_table(df,
index=['지역', '월'],
values=['매출', '비용'],
aggfunc={'매출': 'sum', '비용': ['min','mean', 'max']})
pivot4비용에 대해 min, max, mean 이 각각 표시
추가로 df.reset_index() 사용시 인덱스를 그룹화 하지 않은 열로 변경 가능
반응형
'파이썬(Python)' 카테고리의 다른 글
| 데이터프레임-transform() 활용하기 (2) | 2025.08.18 |
|---|---|
| 파이썬-데이터프레임 변환 melt, pivot 함수 사용하기 (2) | 2025.08.17 |
| 파이썬-데이터프레임 데이터 필터링하기 (4) | 2025.08.14 |
| 파이썬-날짜데이터 포맷 변경하기 (4) | 2025.08.13 |
| 파이썬-피봇테이블(pivot_table) 컬럼 변경하기 (0) | 2025.08.13 |